


Since GPGPU (general purpose computing on graphics processing unit) computing emerged in 2007, the performance gains offered by GPUs have been offset to a degree by a critical bottleneck: moving the data to and from the GPU over PCI Express (PCIe).
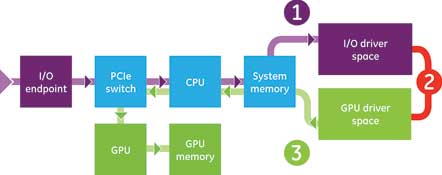
In the past, the GPU was only able to DMA (direct memory access) to/from system memory, routed via the CPU. If the data originated from another PCIe endpoint, such as an FPGA, 10GigE NIC or InfiniBand HCA, the data would first have to be DMA’d to system memory, then in many cases copied in user-space between unshared driver buffers, and then finally DMA’d into the GPU for processing.
Because of the additional hops in system memory, this data path incurred additional latency and decreased bandwidth, which precluded the GPU from being deployed in many real-time applications.
However, beginning with the latest generation of Kepler-family GPUs and CUDA 5.0 from Nvidia, a new feature called GPUDirect RDMA enables third-party PCIe endpoints to DMA directly to and from the GPU, without the use of system memory or the CPU. This results in dramatically lower latencies and efficient PCIe utilisation, as well as decreased CPU overhead.
How it works
Each system’s PCIe address space includes a mapping of system memory, enabling endpoints and their DMA engines to access it, and also sets of base address registers (BAR) for each endpoint.
Traditionally, BARs are used to access an endpoint’s control registers from kernel drivers running on the CPU. However, Nvidia Kepler-family GPUs implement a BAR that provides an aperture into the GPU’s internal memory, which other endpoints can use for DMA. This GPUDirect aperture can map up to 256 MB of internal GPU memory at a time for access by external PCIe endpoints. The aperture is controlled from the user’s CUDA application.
Using the GPUDirect aperture is transparent for the endpoints and requires no changes to the hardware. Since GPUDirect RDMA only relies on previously standardised PCIe DMA operations, integration is of minimal impact. This enables the technology to be integrated with a wide range of already existing PCIe endpoints that support DMA.
In normal operation, where the endpoint’s DMA engine is transferring to/from system memory, the endpoint’s kernel driver populates the DMA engine’s scatter-gather list with the addresses of system memory, which are allocated and provided by the host operating system.
The only change to enable GPUDirect RDMA is that, now, the endpoint’s kernel driver will populate addresses of the GPUDirect aperture instead of system memory addresses. These GPUDirect addresses are provided by the CUDA user API and Nvidia kernel driver.
System topologies
In addition to being flexible from a hardware and software perspective, GPUDirect RDMA is also flexible from a system topology perspective. Multiple endpoints can DMA to/from the same GPU simultaneously. Additionally, there can be multiple GPUs in the system, each of which has its own GPUDirect aperture that can be independently mapped and accessed by one or more endpoints.
In fact, GPUDirect RDMA enables higher GPU-to-CPU ratios than previously seen because of increased GPU autonomy. Thus, CPUs can manage more GPUs (up to 16), in addition to having substantially more CPU headroom left over for serial post-processing.
The user application is responsible for configuring the data flows (e.g. which endpoints DMA to which GPUs and vice versa). Since the underpinnings of GPUDirect RDMA are transparent to external endpoints, the rule of thumb regarding DMA is: if a certain configuration of endpoint(s) were able to DMA to system memory, then they can also DMA to the GPU(s) via GPUDirect RDMA. This also holds true whether or not there is a PCIe switch in the system.
GPUDirect RDMA functions optimally when both the GPU and endpoint are downstream of a PCIe switch, as dedicated switches (such as those from PLX or IDT) route peer-to-peer traffic more efficiently. However, even if the GPU and endpoint are connected to the CPU’s root complex, GPUDirect RDMA will still function correctly.
One thing to note, however, is that multi-GPU systems generally have one or more PCIe switches to achieve the necessary connectivity between GPUs and endpoints.
Applications and performance
GPUDirect RDMA is an ideal solution for those who wish to harness the parallel processing horsepower of the GPU, but whose applications demand real-time, low-latency streaming. One such application is to integrate FPGA sensor interfaces (which receive and/or transmit radar, SIGINT or EW signals, for example) with GPUs for a low-latency, high-bandwidth frontend signal processing pipeline.
Traditionally, the use of GPUs in real-time DSP applications was curtailed by the endpoint→CPU→GPU DMA chain (see Figure 1) but, with the deployment of GPUDirect RDMA, lower latencies can be achieved. As such, the application space for GPUs in signal processing is greatly expanding.
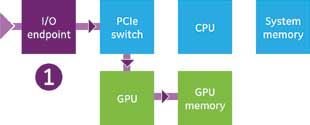
To explore this, it is instructive to review a case study using GE’s 6U VPX IPN251 and ICS-1572 XMC.
The IPN251 is a quad-core, 3rd generation Intel Core i7 integrated with a 384-core Nvidia Kepler GPU, Mellanox ConnectX-3 InfiniBand/10GigE adapter, and XMC site. On the IPN251’s XMC site, the ICS-1572, a Xilinx Virtex-6-based RF interface with two ADC channels and two DAC channels, was mounted.
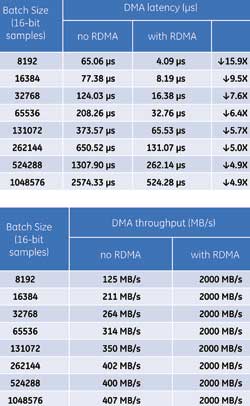
Using GPUDirect RDMA, data was streamed directly from the ICS-1572’s ADCs into the Kepler GPU. Table 1 compares the DMA latency and throughput with and without RDMA enabled. The batch size indicates how many samples were DMA’d and processed at a time. Note that the ICS-1572 uses a PCIe gen1 x8 connection, so the maximum achievable bandwidth is 2 GBps.
Backend interconnects
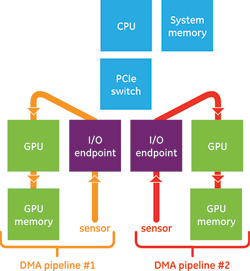
The usefulness of GPUDirect RDMA doesn’t apply only to frontend sensor interfaces; it can also be deployed to achieve lower latencies across backend interconnects for inter-processor communication (IPC). For example, integrating GPUDirect RDMA with InfiniBand HCAs and/or 10GigE NICs permits scalable networks of GPUs that exist across many CPU nodes.
Although GPUDirect RDMA enables ever increasing GPU-to-CPU ratios, a limit is nevertheless reached when multi-GPU systems are broken up to include multiple CPU host nodes. In this case, GPUDirect RDMA is effective and efficient at maintaining low-latency communication between GPUs across the network.
Impacts of GPUDirect RDMA
GPUDirect RDMA solves an age old problem for GPUs by removing the CPU and system memory bottleneck. By doing so, it greatly decreases the latency of streaming data into the GPU from external PCIe endpoints and increases bandwidth through more efficient PCIe intercommunication. This allows the GPU to move into new application domains, like electronic warfare and radar/SIGINT frontends, which were previously inaccessible due to low-latency requirements.
GPUDirect promotes GPU autonomy and frees up CPU resources that were previously dedicated to managing the GPU and copying around memory. Since CPU overhead for each GPU is now minimised, this in turn permits more GPUs to be connected to each CPU and for larger multi-GPU systems to be deployed.
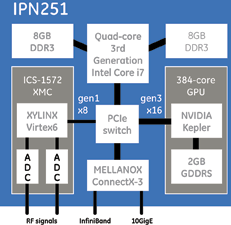
GE Intelligent Platforms’ most recent rugged 3U and 6U VPX products are fully enabled for GPUDirect RDMA, including the 3U GRA112, which features a 384-core Nvidia Kepler GPU, and also the 6U IPN251.
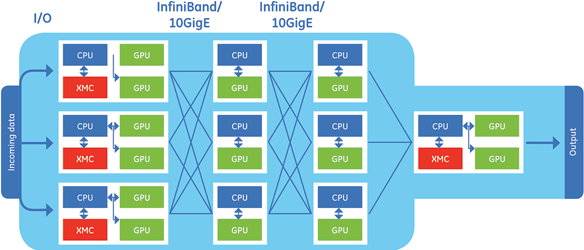
In addition, GE’s sensor processing interfaces, such as the ICS-1572, ICS-8580, SPR870A and SPR507B, have been integrated and tested with GPUDirect RDMA. Moreover, the company’s use of Mellanox ConnectX InfiniBand and 10GigE adaptors allows GPUDirect RDMA to be utilised across backend networks for low-latency IPC as well.
| Tel: | +27 21 975 8894 |
| Email: | [email protected] |
| www: | www.ri-tech.co.za |
| Articles: | More information and articles about Rugged Interconnect Technologies |


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version