


Speech compression allows recording and/or playback applications, such as verbal security alarms, to reduce their storage budget, and allows speech communications systems, such as walkie-talkies, to maximise their bandwidth by reducing their data transmissions. But these advantages come at a cost.
The most commonly used speech compression techniques are based on standard algorithms, such as the International Telecommunications Union’s (ITU) G.728 and G.729, and these standards typically incur significant royalty costs. There are, however, other techniques that can provide comparatively inexpensive speech compression at ratios ranging from 2:1 up to 16:1.
At the higher end of the compression scale, an open-source algorithm called Speex, based on a variant of Codebook Excited Linear Prediction (CELP) compression, can provide inexpensive compression at a high factor of 16:1, whilst also maintaining high speech quality.
At the other end of the spectrum lies simple A-law and μ-law companding (compressing and expanding), specified by the ITU G.711 standard, and providing a 2:1 compression ratio suitable for telephony or other low computational applications. The G.726A compression standard, based on the adaptive differential pulse code modulation (ADPCM) technique, supports a wide selection of compression ratios between those provided by G.711 and Speex. Together, these three algorithms form a versatile suite of speech-compression techniques, providing a number of performance vs. complexity alternatives for cost-sensitive applications.
All of these compression techniques can be implemented using a low-cost embedded platform such as Microchip’s dsPIC digital signal controllers (DSCs). These DSCs integrate a variety of on-chip peripherals which are optimised for speech-compression applications.
Speech-compression techniques
Any speech compression/decompression technique involves sampling an input-speech signal and quantising the sample values, in order to minimise the number of bits used to represent them. This must be performed without compromising the perceptual quality of the encoded speech, defined as the quality of the speech as heard by the human ear, not necessarily a bit-to-bit closeness between the original and reconstructed signals. The choice of encoding algorithm for a particular application depends upon the perceptual quality required at the decoder end, and often involves a trade-off between speech quality, output data rate (based upon the compression ratio), computational complexity and memory budget.
In general, data compression techniques can be broadly classified into lossless or lossy methods. In lossless encoding algorithms, the decoded signal yields a bit-exact reproduction of the original set of samples. Most speech- and audio-compression techniques, however, use lossy algorithms, which rely on removing redundancies inherent in the data or in human hearing, rather than maintaining bit-for-bit accuracy in the decoded signal.
Speech encoding algorithms can also be classified according to the type of data that is quantised. In direct quantisation, the encoded data is simply a binary representation of the speech samples themselves. Alternatively, parametric quantisation encodes a set of parameters that represent various characteristics of the speech. Parametric quantisation can exist as waveform or voice coders (vocoders). Waveform coders encode information about the original time-domain waveform, while removing statistical redundancies in the signal, and can be used for speech and other signals. Vocoders try to model characteristics of the human speech generation system and transmit a set of parameters that help to reproduce speech which has high perceptual quality, without reproducing the waveform itself.
Many common waveform coders are based upon scalar and vector quantisation. In scalar quantisation (such as in the G.711 and G.726 algorithms), samples are processed and quantised individually. In vector quantisation, the samples are encoded in blocks, typically using vector-indexed tables known as codebooks. Vocoders are the method of choice for low bit-rate coders, and for several ITU-standard encoding techniques. Speex is an example of a closed-loop vocoder algorithm, known as analysis by synthesis.
ITU-T G.711: A-law /μ-law companding
Based upon the principle of A-law and μ-law companding, ITU-G.711 is a simple, royalty-free speech code which has an input sampling rate of 8 kHz, and is widely used for voice communications over telephone networks.
European and International telephone networks use the A-law companding format, whereas μ-law is used in the USA, Japan and many other countries. Both formats are also used by hands-free kits and other Bluetooth wireless devices, as well as by many analog-to-digital and digital-to-analog codec devices for communicating with microcontrollers or DSCs.
Unlike basic uniform pulse code modulation (PCM), where the signal’s dynamic range is divided into equal steps, G.711 uses non-uniform quantisation step sizes. The step sizes are allocated logarithmically, with finer steps, and therefore greater precision, for smaller rather than larger amplitudes. The step sizes, therefore, are closely related to the probability-density function of speech signals, in which smaller signals occur more frequently. Essentially, this technique makes the signal-to-quantising-noise ratio independent of signal variance. Figure 1 illustrates the effect of A-law or μ-law compression on the uniform PCM samples.
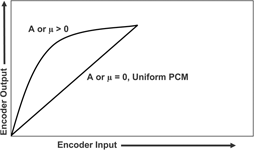
In both A-law and μ-law companding, a mapping function is applied individually to each input sample, to convert it to a form where uniform quantisation can then be used:
A-law
- sgn(x) * A|x|/(1 + log(A)) when |x| < 1/A
- sgn(x) * (1 + A|x|)/(1 + log(A)) when 1/A ≤ |x|≤ 1 μ-law
- sgn(x) * (1 + μ|x|)/(1 + log(μ))
These equations demonstrate that the specifics of the mapping function differ slightly between A-law and μ-law. For example, the data size of the input samples is 13 bits with A-law, and 14 bits in μ-law. Instead of calculating the mapping function values based on a specific value of A or μ, the G.711 coder uses standard lookup tables to perform the mapping, using the same basic logarithmic quantisation methodology.
The G.711 algorithm encodes 13-bit or 14-bit data samples into 8-bit output samples. If the input data samples are stored in 16-bit words, which is the native data width of most fixed-point digital signal processors (DSPs), the coder provides a 2:1 compression ratio. An 8 kHz input sampling rate will therefore correspond to a 64 Kbps output data rate.
On the decoder side, the encoded samples are expanded back to uniform PCM samples using a reverse mapping process, which reproduces the original speech signals. The quality of this decoded speech, as measured by the subjective mean opinion score (MOS) graded on a scale of 0 to 5, is between 4,3 and 4,5. For human perception, this is almost indistinguishable from the original speech.
ITU-T G.726A: adaptive differential PCM (ADPCM)
The ITU standard G.726A coder is a variant of the G.726 speech coder, which is another immensely popular scalar quantisation technique. The principle difference is that G.726 assumes that input samples are in A-law or μ-law encoded format, whereas G.726A operates on 14-bit uniform PCM input samples which eliminates the need for additional G.711 encoder/decoder functionality.
Data rates of 16 Kbps, 24 Kbps, 32 Kbps and 40 Kbps are supported by G.726A, with the higher data rates providing significantly higher MOS for speech quality. For example, at 40 Kbps and 32 Kbps, the MOS is 4,5 and 4,4 respectively. This decreases to 4,1 at 24 Kbps and 3,4 at 16 Kbps. These data rates cover a wide range which falls between those of G.711 and low bit-rate coders.
The G.726A algorithm is based upon the principle of ADPCM which, like all differential PCM coding schemes, compresses data by removing redundancies in the input data stream. This exploits the fact that adjacent speech samples are highly correlated. In the simplest case, the difference between two adjacent samples can be quantised using far fewer bits than would be required to quantise the samples themselves, which reduces the overall number of bits needed to represent the waveform.
In practice the difference, or error signal, between the current sample and a linear combination of past samples is quantised to provide the encoder output that may either be transmitted or stored. G.726A quantises each error value using 5 bits in the 40 Kbps mode, 4 bits in the 32 Kbps mode, 3 bits in the 24 Kbps mode and 2 bits in the 16 Kbps mode. The process of predicting the current input sample by filtering past samples is known as a prediction filter.
In an ADPCM algorithm, the coefficients of this prediction filter are not fixed, but continually change based on the encoded error values and a reconstructed version of the original signal. In many algorithms, the quantiser used to quantise the error signal is itself adaptive. Similarly, in some algorithms, the quantiser scale factor and quantiser adaptation speeds are iteratively adjusted, based on the error values and prediction-filter coefficients. In fact, this approach is stipulated in the G.726A standard. Figures 2 and 3 are simplified block diagrams of the G.726A encoder and decoder.
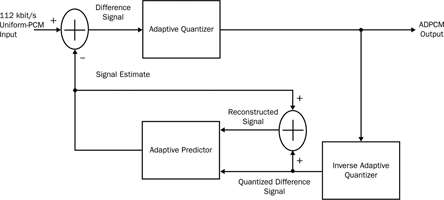
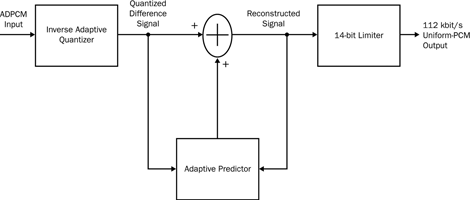
The G.726A encoding algorithm uses a prediction filter with eight coefficients: two poles and six zeros. These coefficients are adapted using a gradient algorithm that minimises the mean square of the error values of, for example, the encoder output. Backward adaptation is used, so that the prediction filter parameters are estimated from past speech data, as opposed to forward adaptation, where current speech data is used. This has a significant advantage as the past speech data is already available at the decoder end. The decoder can therefore mimic the prediction filter update, without requiring the encoder to transmit prediction-filter coefficients. In fact, the only data that the encoder transmits to the decoder is the quantised error signal, which allows minimal use of the communication bandwidth.
Speex: codebook excited linear prediction (CELP)
While ITU-T G.711 and G.726A suit applications with medium- to high-output data rates, a different algorithm is needed for designs which need low output data rates of 8 Kbps and below. Most algorithms that perform at this level of compression use models of speech production and involve parametric quantisation. Some do not produce the quality necessary for many communication and speech record/playback applications, while others produce a reasonable MOS in a way that is computationally prohibitive for many low-cost embedded applications. Several ITU, mobile communication and other standards exist for low bit rates, such as the ITU-T G.729, G.728 and G.723.1 standards. However, a common feature of most of these algorithms is that they involve significant royalty costs. One exception to this trend is the open-source Speex algorithm, which is based upon the CELP algorithm.
The Speex algorithm supports a wide variety of output data rates, including a variable bit-rate mode, where the output data rate varies to maintain a pre-specified level of speech quality. Additionally, this algorithm supports three different input sampling rates of 8 kHz (narrowband), 16 kHz (wideband) and 32 kHz (ultra-wideband). The following example is based on narrowband mode, with an output data rate that remains constant at 8 Kbps. This mode provides a 16:1 compression ratio, and is suitable for a wide variety of communication and voice record/playback applications. The input speech samples are processed in blocks of 160 samples, resulting in an output-encoded frame that contains 20 Bytes of data.
The Speex algorithm also provides an optional voice activity detection feature, which can reduce the number of bits used to encode intervals that do not contain any speech. Specifically, non-speech frames are encoded using 5 Bytes instead of 20 Bytes, which is just enough to reproduce the background noise. This feature should not be used when deterministic bit rates are required, for example in communications between two walkie talkies.
The major algorithmic functions of the Speex algorithm are linear prediction, pitch prediction, the innovation codebook, and error weighting.
Linear prediction
The Speex algorithm works on the principle of encoding a speech signal in terms of a set of parameters that model vocal tract and excitation. This is done using a 10-tap linear prediction filter. This filter models the vocal tract, especially the formant structure inherent in the vocal-tract response. The filter coefficients are then quantised, providing some bits in the encoded data structure. This is known as short-term prediction, as only a small number of past samples are filtered to estimate the current sample.
The linear-prediction filter’s output is given by:
Y[n] = Σ(ai * x[n-i])
where i = 1, 2, …, 10
The prediction error, also known as the excitement, is therefore:
e[n] = x[n] – y[n]
The linear prediction filter coefficients are iteratively adapted by minimising the mean-squared prediction error, which is given by:
E = Σ[e[n]]²
where n = 0, 1, 2, …, 159
This criterion is fulfilled when the following equation is solved using the Levinson-Durbin algorithm:
R * a = r
where R is the autocorrelation matrix and
r is the autocorrelation vector.
The resulting coefficients are converted into a line spectral pair formulation, to improve their robustness during quantisation.
Pitch prediction
During voiced speech segments, short-term prediction is complemented by a long-term prediction that tries to model the vocal chord by exploiting the periodic nature of voiced speech. The excitation signal is approximate to the product of the pitch gain and pitch period, as follows:
e[n] = p[n] = β * e[n-T]
where β is the pitch gain and T (T >> 10) is the pitch period
Innovation codebook
The final excitation signal can be found with the sum of the pitch prediction, and a parameter searched from a fixed codebook, known as the innovation codebook. This codebook entry represents the residual information that the linear and pitch prediction failed to capture.
e[n] = β * e[n-T] + c[n]
where c[n] is the innovation codebook entry.
Error weighting
Before optimising the prediction filter coefficients, the signal is pre-filtered by a weighting filter in order to modify the frequency characteristics of the noise so that it is mainly present in the parts of the frequency spectrum where the human ear cannot perceive it clearly.
The structure and contents of the Speex-encoded data frame are shown in Table 1.
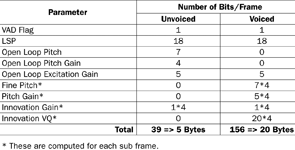
Compression vs. quality
For low data-rate applications, the simple G.711 coder provides a 2:1 compression ratio. At the other end of the spectrum, the Speex coder provides an open-source implementation of a complex CELP-based algorithm, which provides a 16:1 compression ratio, as well as many others supported by the coder. The centre ground is occupied by the ADPCM-based G.726A coder, which provides multiple compression ratios, including 4:1 and 8:1.
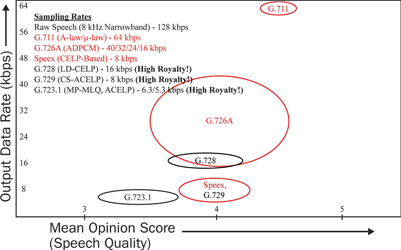
Figure 4 illustrates the trade-off between output data rate, and therefore the compression ratio, and the MOS quality of decoded speech for different speech coding algorithms. It is apparent that the open source Speex algorithm provides a similar range of characteristics, compared to the expensive G.729 algorithm.
Computational overheads
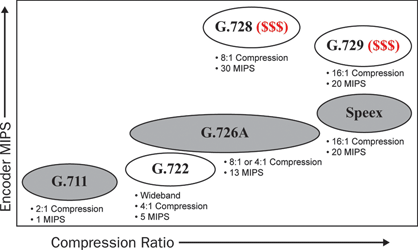
Figure 5 shows the relationship between the MIPS requirements of various speech encoding algorithms and the resulting compression ratio. As expected, coders with higher compression ratios, such as Speex and G.729, use more complex, parametric computations and filter adaptations, and therefore require greater computation resources. Again, the Speex and G.729 have similar requirements. At the other end of the scale, the G.711 coder extensively uses lookup tables and usually requires less than 1 MIPS on most processors.
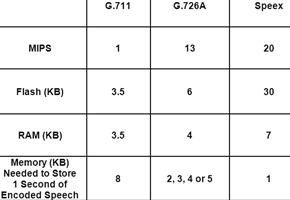
Finally, Table 2 shows the MIPS, Flash memory and RAM requirements of the three royalty-free algorithms using Microchip dsPICs. The MIPS, Flash and RAM usage increases significantly, with the more complex coding algorithms such as Speex. Also, encoding requires many more MIPS than decoding. For example, of the 20 MIPS required for Speex encoding and decoding, 16 MIPS are used by the encoding algorithm, which implies that applications that only require speech playback, and do not need speech recording or communications, use substantially fewer computational resources.
In addition to the sufficient CPU bandwidth and DSP capabilities of processors that execute speech encoding and decoding algorithms, the availability of peripherals is also a key enabling feature. For example, a flexible codec interface, particularly with DMA support, can provide an efficient communication channel for receiving and encoding input speech samples, as well as playing back output samples after decoding. Alternatively, an on-chip analog-to-digital converter (ADC) and pulse width modulation (PWM) module can serve as a low-cost sampling interface in cost-sensitive applications where the cost of using an external codec may be prohibitive.
Conclusions
Cost-sensitive applications across a range of data rates can benefit from royalty-free speech compression by using the ITU-T G.711, G.726A and Speex algorithms. Each of these algorithms can be implemented on dsPIC DSCs, and provides a different range of functionality, bit-rate and computational complexity. This eliminates the high cost of royalties associated with the more commonly used G.728 and G.729 algorithms, in a wide range of speech compression applications.
References
1) 'Speech Coding: A Tutorial Review', Andreas S. Spanias, Proceedings of the IEEE, Vol. 82, No. 10, October 1994.
2) ITU-T Recommendation G.711: 'Pulse code modulation (PCM) of voice frequencies'.
3) ITU-T Recommendation G.726: '40, 32, 24, 16 Kbit/s adaptive differential pulse code modulation (ADPCM)'.
4) ITU-T Recommendation G.726 - Annex A: 'Extensions of Recommendation G.726 for use with uniform quantized input and output'.
5) 'The Speex Codec Manual (version 1.0)', Jean-Marc Valin, March 2003.
| Email: | [email protected] |
| www: | |
| Articles: | More information and articles about Tempe Technologies |


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version