


Multi-layer convolutional neural networks have led to state-of-the art im-provements in the accuracy of non-trivial recognition tasks such as large-category image classification and automatic speech recognition. These models are computationally expensive and resource-consuming. The implementation of convolutional neural networks on embedded devices can be problematic since these platforms are resource, power and space constrained.
In this article, a framework, developed by ASIC Design Services, for accelerating convolutional neural networks on FPGAs is introduced. The framework is a scalable and flexible embedded deep learning solution that allows for the implementation of a wide range of convolutional neural networks on FPGAs.
Background
Traditional image processing techniques used hand-crafted features combined with a trainable classifier. The features served as a unique, compact and informative representation of the input image. The classifier uses the features for subsequent learning and inference. This classifier may have been as simple as a naive threshold technique or something more complex, such as a support vector machine or a feedforward neural network.
Using hand-crafted features proved to be difficult, especially for novices in image processing, since the design is time consuming and in some cases the features are highly application specific. These techniques also required in-depth data analysis to understand the underlying distribution of the features in the data. For noisy input data, hand-crafted features can produce inconsistent representations resulting in erroneous classification results.
Using trainable features has solved many of these problems, since the features themselves are learned from the same data used to train the classifier. In the late 1980s, LeCun had success with the idea of using a trainable feature extractor combined with a trainable classifier for classifying digits[1]. The approach became widely known as convolutional neural networks (CNNs).
The approach offers an attractive solution for several machine learning problems such as scene labelling and other computer vision tasks[2]. Many vision tasks also lend themselves to embedded applications such as robots, unmanned aerial vehicles and surveillance cameras. Limited on-board processing and power resources as well as total solution size constrain the intelligence that can be implemented on these edge/node devices. The computational demands and bandwidth requirements of CNNs make it difficult to utilise the power of these algorithms on embedded platforms.
General purpose GPU (graphics processing unit) computing has been used with great success to accelerate the performance of CNNs. A major drawback of these devices is that they have high power requirements. Furthermore, GPUs are quite big, rendering them unsuitable for many embedded applications.
Field programmable gate arrays (FPGAs) have long been used to accelerate high-speed algorithms in hardware. The Core Deep Learning framework developed by ASIC Design Services and introduced in this article exploits the advantages of FPGAs for accelerating CNNs.
Why FPGAs for moving the processing to the node/edge
Over the past decade, the amount of resources available on FPGAs has increased significantly and the amount of fabric memory, multiplier accumulate (MACC) units and logic elements on these devices allow for considerably improved computation throughput.
Unlike GPUs, FPGAs have a flexible hardware configuration as they are programmable and offer high energy efficiency, as well as a significant drop in power requirements. Some FPGAs have a Flash Freeze mode that yields extremely low standby power. This can be beneficial for applications that do not require a high frame rate as the FPGA only needs to be woken up upon some external interrupt, e.g. person recognition in a surveillance application where the external interrupt is a motion sensor.
Time multiplexed operation, enabled by Flash Freeze capable FPGAs, can also dramatically reduce power consumption in battery powered and low-power applications. The total solution size/footprint is also very small, and the total real estate required for some modern FPGAs can be as little as 121 mm². All these advantages make FPGAs an attractive hardware platform to accelerate CNNs.
Convolutional neural networks in general
A typical CNN has two primary components: a feature extractor and a classifier, as shown in Figure 1. The feature extractor consists of cascaded convolution layers that are highly processing intensive. The classifier, on the other hand, consists of stacked, fully connected neural network layers, sometimes referred to as dense layers, that are primarily memory intensive.

Convolution layers
Figure 2 shows the structure of a standard convolution layer. The layer has M number of output feature maps and N number of input feature maps. Each output feature map has R rows and C columns. The convolution layer performs a unique filtering operation for each input-output feature map combination. The K x K kernel weights associated with each input-output feature map combination are trainable. A stride, S, can also be specified for the convolution operation.
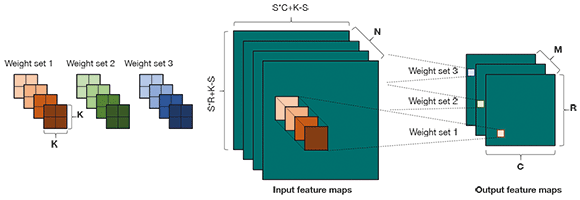
The primary operation for this type of layer is a multichannel convolution. Each output feature map is not just the results of a simple convolution over a single input feature map, but rather the combination of convolutions over all input feature maps. With each cascaded convolution layer, the feature extractor can learn progressively more complex and abstract feature representations of the input data.
Fully connected layers
Figure 3 shows an overview of fully connected layers. Every input node is connected to every output node and a weight is associated with each connection. The fully connected layer applies a linear transformation on the input vector. The Figure on the right depicts a more detailed view of the operations within a fully connected network.
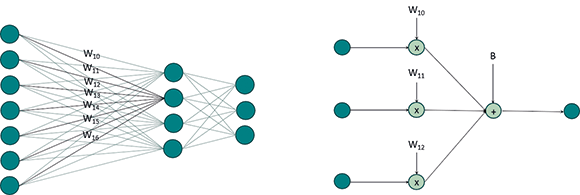
The value of the output node is simply the inner product of the input nodes and the weights. A bias, B, is also added to the result. The bias and weights in a fully connected layer are all trainable. Stacking multiple fully connected layers increases the expressive power of the classifier and allows the network to learn a non-linear transfer function for the classification phase.
Other layers in a CNN
Together with the convolution and fully connected layers there are two other layers that are also widely used in CNNs. Non-linearity or activation layers allow the network to learn higher-order representations of the input. Pooling or subsampling layers, on the other hand, provide translation invariance and remove unnecessarily detailed processing to improve performance.
Furthermore, there are also variations in convolution layers, such as depth and point-wise convolution layers. The focus of this article will not be on these layers and the reader is referred to the many online resources that are available on CNNs for more detailed discussions.
Convolutional neural networks on FPGAs
FPGAs have limited resources such as multiplier units, logic elements and fabric memory. Considering these limitations there are two components that need to be investigated when reviewing the possibility of implementing CNNs on an FPGA and exploring the design space. The computing throughput as well as the required memory bandwidth needs to be examined.
Deep CNN models can have extremely high computation complexity with up to 40 billion multiplication and addition operations. Furthermore, the size of these models requires the use of external memory since the entire network will rarely fit into the fabric memory available on most FPGAs.
Figure 4 shows the time and space complexity analysis of a typical CNN where the first five layers of the CNN are convolution layers and the last two layers are fully connected layers. The time complexity of a layer is measured in the amount of operations that need to be performed, whereas the space complexity is determined by the amount of weights that need to be retrieved from external memory.
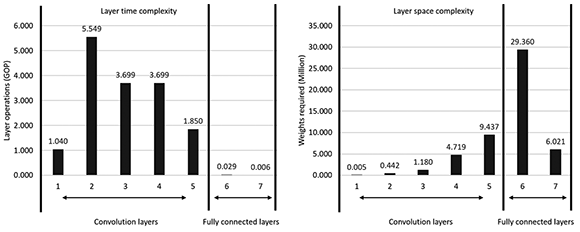
From the Figures, it is apparent that the convolution layers require very little bandwidth compared to the fully connected layers. On the other hand, the fully connected layers are a lot less computationally demanding than the convolution layers.
Reads and writes to external memory can be expensive depending on the memory bandwidth available. If the memory bandwidth cannot match the computing throughput or vice versa then either the logic resources or memory bandwidth is under-utilised. The goal is thus to maximise the computational throughput by exploiting parallelism while concurrently minimising the amount of memory access by identifying shared memory and quantisation. Exploring the design space for implementing CNNs on an FPGA is a non-trivial task.
Core Deep Learning
The Core Deep Learning framework was developed for accelerating CNNs on an FPGA. The aim of the framework and the design considerations were as follows.
1. The framework had to utilise all the different sources of parallelism within a CNN.
2. Effective data compression techniques that reduce the memory footprint while still preserving the network accuracy had to be implemented.
3. The framework had to be scalable and generative of nature. Hereby the framework should rather be a CNN FPGA core generator than a fixed implementation for accelerating CNNs on an FPGA.
4. The framework had to support all the different layers and features that form part of a common CNN.
5. The framework had to allow for a flexible solution where performance, power and resource utilisation could be chosen to allow for a hardware specific, network specific, optimised design to be generated.
Framework overview
Figure 5 shows the Core Deep Learning framework flow consisting of four phases. With all the challenges mentioned above, implementing CNNs on an FPGA can be difficult due to the computational and external memory bandwidth constraints. Furthermore, the learning curve for FPGA development is steep and can prove difficult for inexperienced users.

The Core Deep Learning framework bridges this gap by allowing a user to go from high-level network specification to FPGA implementation with minimal effort. The framework takes as input a high-level CNN description and produces as output a synthesisable SystemVerilog core.
Network description
For the network description, the CNN architecture is specified using the Caffe format[1]. Support for other frameworks such as TensorFlow is planned for future implementations.
The framework supports the following common deep learning layers/operations:
• Convolution layer.
• Depthwise convolution layer.
• Fully connected layer.
• Concatenation layer.
• Residual layer.
• Pooling layer.
• Activation layer.
The convolution layers support padding (same and valid), any kernel size and any kernel stride. Pooling layers support any kernel size. Any activation layer that can be implemented as a lookup table is supported by the framework. Batch normalisation is also supported. For the fully connected layers any amount of input nodes and output nodes are supported.
Compression
The available on-chip memory and external memory bandwidth on FPGAs are highly constrained. Reducing the amount of data transfers can ease the bottleneck to the external memory. To reduce the amount of data transfers, the network data and trainable parameters need to be compressed. The Core Deep learning framework implements quantisation as a compression solution.
One of the biggest concerns is how quantisation will affect the accuracy of the network, especially considering the weights and data used in neural networks are generally 32-bit floating point. Research has shown that this 32-bit floating point representation is not necessary to keep the same level of accuracy[4-5].
The compression step in the framework implements a re-training and quantisation operation where the 32-bit floating point parameters of the CNN are converted to 8-bit fixed-point parameters. The range of the weights and data in different layers of the network can differ significantly. The solution lies in a dynamic 8-bit fixed-point approach, where the location of the radix point is variable for each layer and its set of weights, as shown in Figure 6.

The multiply-accumulate operations in the layer are performed at a high precision, thereafter a set of eight consecutive bits is selected and passed on for further processing. The location of the radix point for each layer and each set of weights is selected during design, by analysing the network using a representative test set. During the analysis the location of the radix point that results in the smallest difference between the quantised version and original version of the layer and weights is determined.
Design space exploration
In a CNN there are several sources of parallelism. The inherent parallelism of FPGAs means that these devices can possibly utilise all the sources of parallelism in CNNs. It is important to note the data dependency between layers. The output feature maps of the previous layer are the input feature maps of the current layer. For this reason, layers cannot be processed in parallel. Furthermore, due to the size of most CNNs, it is not possible to implement the entire network on the FPGA in a pipelined fashion.
Looking at the standard structure of a convolutional layer as shown in Figure 2, the following sources of parallelism in CNNs can be identified.
1. Kernel level parallelism: Within each convolution there exists parallelism. The multiplication and addition operations for a single kernel can be done in parallel.
2. Input feature map parallelism: Each input feature map can be processed independently. Convolutions on different input feature maps can thus happen in parallel.
3. Output feature map parallelism: Each output feature map has a set of kernels associated with each input feature map. This means that convolutions share the same input feature maps but not the same kernels. This in turns means that different output feature maps can be processed in parallel.
In a deep CNN, it is not always possible to implement all the sources of parallelism. The limited bandwidth and on-chip resources restrict the amount of parallelism that can be implemented, and the design space needs to be explored based on these constraints.
A common method to address these challenges is to implement tiling and data reuse. A single input feature map can be tiled by only considering part of the input image at a specific time. Furthermore, tiling over the input and output feature maps of a layer can also be done. Only a certain amount of input feature maps is considered to compute a partial result for a certain slice of the output feature maps.
All these methods introduce parameters that need to be selected beforehand. With each parameter the design space increases and selecting the optimal design can be very difficult. To solve this problem the Core Deep Learning framework implements a design space exploration phase.
As discussed in previous sections, a CNN implementation can be either computation or memory bandwidth constrained. To obtain the optimal implementation, it is necessary to model the performance to off-chip memory traffic.
The roofline model is shown in Figure 7. The model relates performance, operational intensity and memory performance together in a two-dimensional graph[6]. The horizontal line shows the peak performance. The maximum memory bandwidth defines the slope of the bandwidth roof line. The maximum attainable performance for an application on specific hardware can be calculated by
where CTC ratio is the computation to communication ratio and BW is the maximum attainable bandwidth. The performance can be no higher than the two values. The computational roof specifies the peak performance and the second term bounds the maximum performance that the memory system can support for a given CTC.
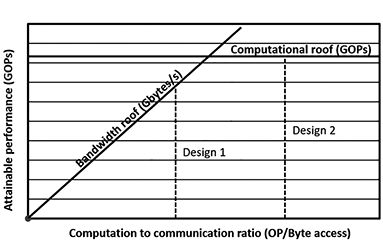
The Core Deep Learning framework implements the roofline model to explore the vast design space created by the different design parameters. In Figure 7, the Design 2 has higher computation to communication ratio, or better data reuse than Design 1. In Design 1 the computational resource is under-utilised. Using the roofline model, the best design can be selected by considering the user defined requirements as well as platform constraints.
Core Deep Learning
The result of the first three phases of the framework is a synthesisable SystemVerilog core. The core is optimised for the specific CNN and hardware that was defined. This SystemVerilog core is called Core Deep Learning and is the final output of the Core Deep Learning framework.
Figure 8 shows an overview of the Core Deep Learning architecture. The Control IP is the user’s control interface to Core Deep Learning. The core requires external memory to store the network parameters and to use as working space for intermediate results/calculations. The amount of external memory required is dependent on the application and CNN size.
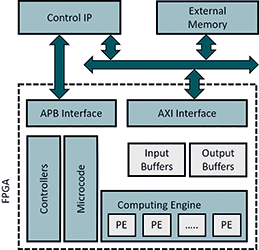
Core Deep Learning is implemented on the FPGA only and does not require an external processor to perform any deep learning functionality. There are several components that make up the core. The interface to the core is an APB and AXI interface. Data transferred from external memory is stored locally in buffers on the FPGA. These buffers are mainly implemented using embedded SRAM blocks.
The computing engine performs all mathematical operations and utilises the embedded math blocks. Lastly, the core implements several controllers to facilitate data transfer and working between the different components. The structure of the buffers, computing engine and controllers are all optimised during the design space exploration phase of the framework.
The Core Deep Learning interface is extremely simple. Since the core is an application specific and network specific implementation there is no run time configuration. The core is set up and started via an APB interface. There is a single bit that can be polled or added to an interrupt routine for when the network is done processing and the next input can be loaded.

Results
The Core Deep Learning framework was tested using the Microsemi SmartFusion2 security evaluation kit and Microsemi PolarFire evaluation kit[7-8]. The SmartFusion2 kit is fitted with an M2S090 FPGA whereas the larger PolarFire kit is fitted with the MPF300T FPGA. Microsemi FPGAs were chosen for their low-power capabilities and optimal MACC unit configuration options. LPDDR and DDR3 were used for external memory on the SmartFusion2 and PolarFire kits respectively.
The evaluation boards were connected to a laptop via an Ethernet link. The laptop was only used to upload new input data and read back the results after the FPGA was done processing. In this section the effect of the compression on the accuracy of the implementations is investigated. Furthermore, the performance results for several CNN implementations generated with the Core Deep Learning framework are given.
Evaluating the effect of compression
Naturally, it is expected that the network will lose some accuracy when implementing quantisation due to decreased representation power, but it was found that it was not as significant as expected. In fact, tests of the standard LeNet CNN structure on the well-known MNIST dataset showed an increase in accuracy. Before quantisation the network had an accuracy of 99,12% and after quantisation the network accuracy increased by 0,03% to 99,15%.
Implementation of the scene labelling network (described in the next experiment) on the FPGA caused an insignificant drop in accuracy of 1% after quantisation. Tests of the popular VGG-16 network on the ImageNet 2012 dataset, where colour images are classified as one of 1000 classes, showed a small drop in accuracy. The 32-bit floating point accuracy was 88,45% and after quantisation the accuracy dropped to 87,54%. In cases like these, the accuracy drop can be rectified or partially addressed by fine-tuning the weights of the network for the quantised format.
Both the LeNet and VGG-16 network examples were of a classification nature, where the output of the network is a single class for each image or pixel. In such tasks it is only important that the value of the output unit corresponding to the correct label is higher than that of competing classes.
The other major machine learning task is regression, where exact output values are of interest. In addition to the 8-bit representation of the output, which limits the resolution, the 8-bit representation may cause saturation inside the neural network, thereby limiting the accuracy of the output. Figure 10 shows the output of a facial keypoint network as implemented on the FPGA. The network gives as output the coordinates of the five facial keypoints.

The network was trained using Kaggle facial keypoint detection dataset[9]. The green keypoints are the points detected by the non-quantised network whereas the red keypoints show the results of an 8-bit dynamic fixed-point network implementation. The strong overlap between the red and green keypoints shows that the regression task was still successful even though an 8-bit representation was used for the FPGA implementation.
Qualitative evaluation
Scene labelling is a semantic segmentation task, where each pixel of the input image needs to be assigned a label. Figure 11 shows the visual results of a scene labelling CNN that was implemented on the SmartFusion2 evaluation kit using the framework. The dataset used to train the scene labelling network is available online[10].

In Figure 11, the image on the left is the input image. The image in the middle is the classified/segmented image and the image on the right shows an overlay of the first two images. In the centre image, yellow represents the sky, purple the trees, brown the buildings, orange the roads and green indicates foreground objects.
Evaluating performance of the framework
In this experiment the performance results for the Tiny-YOLOv2 network[11] is given. The network is based on the original YOLOv2 network[12]. TinyYOLOv2 is much faster than the original YOLOv2 but is less accurate. The YOLO networks can best be described as real-time object detection networks. In the results that follow an operation is defined as a multiply-accumulate operation. The Tiny-YOLOv2 network is a 7 GOPs network. The network was trained on the PASCAL VOC dataset that consists of 20 object classes.

Table 1 shows the FPGA resource utilisation and Table 2 shows the performance for the Tiny-YOLOv2 network running on the Microsemi SmartFusion2 and PolarFire kits. The core frequency was set to 166 MHz, although this can easily be increased to 200 MHz if better performance is required.
Figure 12 shows the visual results for the Tiny-YOLOv2 network implemented on the PolarFire kit. The images are part of the testing data in the PASCAL VOC dataset.

Conclusion
The reconfigurability, power efficiency, low power requirements and security advantages of FPGAs make these devices a viable solution for moving intelligence to the node/edge. The implementation of CNNs on embedded platforms can be challenging. Considering the different sources of parallelism, minimising the memory footprint through data quantisation and exploring the design space allows for an efficient chip specific, network specific implementation of CNNs on a FPGA.
The Core Deep Learning framework can greatly assist in reducing the engineering time needed for bridging the semantic gap between high-level model specification and FPGA implementation of CNNs. The results show that the framework can produce FPGA implementations of computationally expensive CNNs for both small and large FPGA devices that run in real-time.
References
1. Y. Lecun, L. Bottou, Y. Bengio and P. Haffner: ‘Gradient-Based Learning Applied to Document Recognition,’ in Proceedings of the IEEE, Vol. 86 No. 11, pp. 2278-2324, Nov 1998.
2. A. Krizhevsky, I. Sutskever, and G. E. Hinton: ‘ImageNet Classification with Deep Convolutional Neural Networks,’ in Neural Information Processing Systems, pp. 1097-1105, 2012.
3. Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, T. Darrell: ‘Caffe: Convolutional Architecture for Fast Feature Embedding,’ in arXiv:1408.5093, 2014.
4. T. Dettmers: ‘8-Bit Approximations for Parallelism in Deep Learning,’ Computing Research Repository, Vol. abs/1511.04561, 2015.
5. P. Gysel, M. Motamedi and S. Ghiasi: ‘Hardware-oriented Approximation of Convolutional Neural Networks,’ Computing Research Repository, Vol. abs/1604.03168, 2016.
6. S. Williams, A. Waterman, and D. Patterson: ‘Roofline: An Insightful Visual Performance Model for Multicore Architectures,’ in Proceedings of the Communications of the ACM, Vol. 52 No. 4, pp. 65-76, Apr 2009.
7. ‘SmartFusion2 Security Evaluation Kit,’ [Online]. Available: https://www.microsemi.com/products/fpga-soc/design-resources/dev-kits/smartfusion2/sf2-evaluation-kit
8. ‘Polarfire Evaluation Kit,’ [Online]. Available: https://www.microsemi.com/products/fpga-soc/design-resources/dev-kits/polarfire/polarfire-eval-kit
9. ‘Kaggle Facial Keypoint,’ [Online]. Available: https://www.kaggle.com/c/facial-keypoints-detection
10. ‘Stanford Background Dataset,’ [Online]. Available: http://dags.stanford.edu/projects/scenedataset.html
11. ‘Tiny YOLO,’ [Online]. Available: https://pjreddie.com/darknet/yolov2/
12. J. Redmon and A. Farhadi: ‘YOLO9000: Better, Faster, Stronger,’ in arXiv:1612.08242v1, 2017.
For more information contact Robert Green, ASIC Design Services, +27 (0)11 315 8316, [email protected], www.asic.co.za
| Tel: | +27 11 315 8316 |
| Email: | [email protected] |
| www: | www.asic.co.za |
| Articles: | More information and articles about ASIC Design Services |


© Technews Publishing (Pty) Ltd | All Rights Reserved
 printer friendly version
printer friendly version